
La première question que posent nos clients quand on aborde l'IA dans leurs projets, c'est rarement « quel modèle ? ». C'est « où tournent les données ? ». Et c'est précisément la bonne question.
Confier vos données métier — contenus éditoriaux, documents clients, code source propriétaire — à l'API d'OpenAI ou d'Anthropic, c'est un arbitrage de souveraineté. Dans certains contextes, il est acceptable. Dans d'autres — secteur public, données sensibles, conformité RGPD stricte — il ne l'est tout simplement pas. Et même quand il l'est, la dépendance à un fournisseur externe a un coût réel : latence, disponibilité, tarification capricieuse, absence de maîtrise sur les mises à jour de modèles.
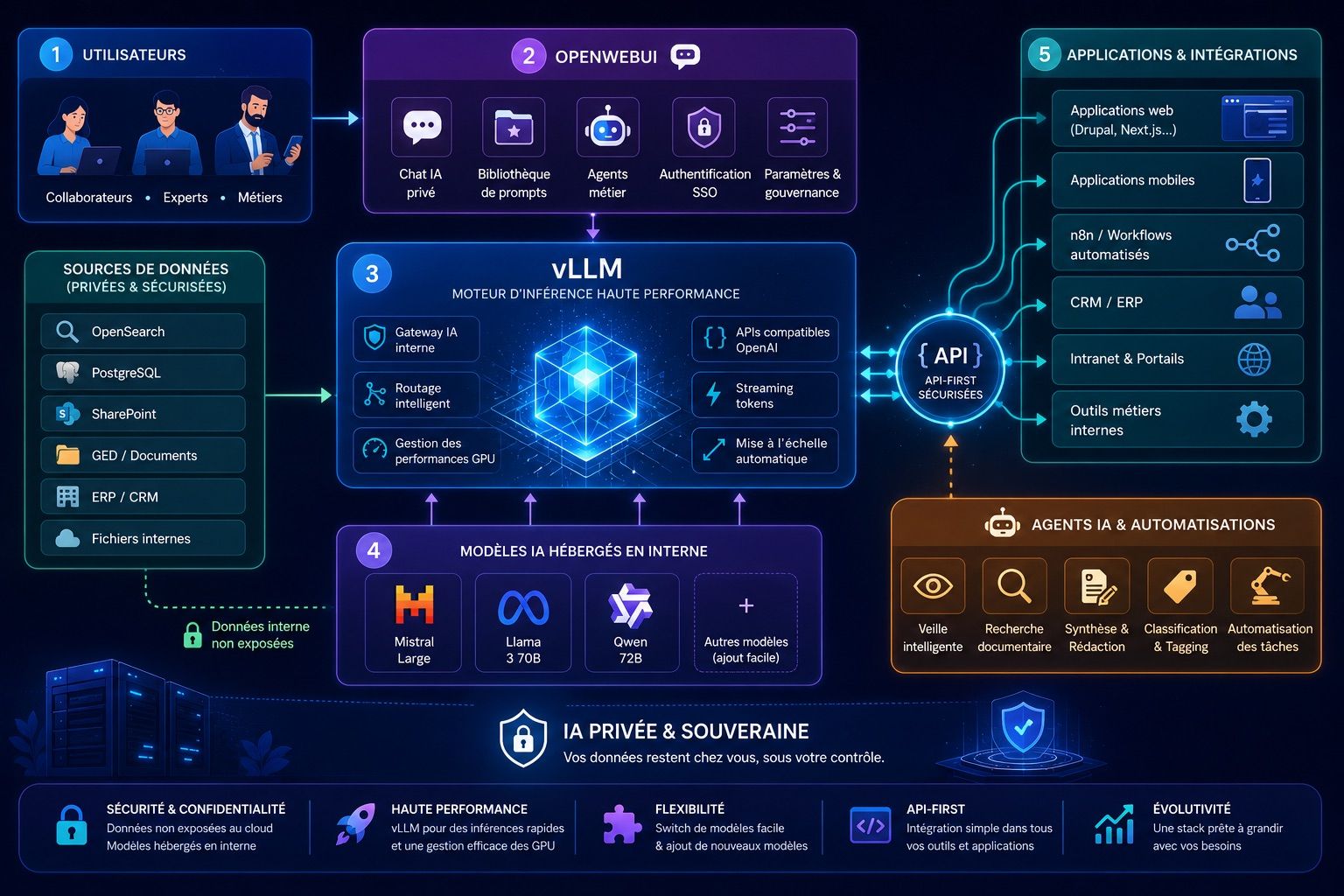
La réponse, c'est une stack IA privée. Encore faut-il savoir assembler correctement OpenWebUI, vLLM et une architecture API-first — voici comment nous le faisons.
Le trio gagnant : vLLM, OpenWebUI et l'API-first
vLLM — le moteur d'inférence
vLLM est un serveur d'inférence open source haute performance pour les LLMs. Il expose une API compatible OpenAI (/v1/chat/completions, /v1/completions) — ce qui signifie que tout client écrit pour OpenAI fonctionne sans modification avec vLLM en backend.
Sa particularité technique : le PagedAttention, un mécanisme d'allocation mémoire GPU qui permet de faire tourner des modèles de grande taille avec une empreinte mémoire optimisée, tout en gérant plusieurs requêtes en parallèle. Sur des charges soutenues, le débit est nettement supérieur à une inférence naïve via Transformers ou Ollama.
vLLM supporte la plupart des modèles Hugging Face : Mistral, Llama, Qwen, Phi, Gemma, et leurs variantes fine-tunées.
OpenWebUI — l'interface et l'orchestration légère
OpenWebUI est une interface web auto-hébergeable pour interagir avec des LLMs. Voyez-le comme un ChatGPT privé : historique des conversations, gestion des modèles, support des documents (RAG), gestion des utilisateurs et des permissions.
Au-delà de l'interface, OpenWebUI expose sa propre API et supporte les Pipelines — des chaînes de traitement programmables qui permettent d'intercepter les requêtes, d'appliquer des filtres, d'orchestrer plusieurs modèles ou d'intégrer des outils externes. C'est là qu'il prend tout son intérêt dans une architecture agent.
L'architecture API-first — le ciment
Ces deux composants sont des services avec des APIs bien définies. Ce qui les fait fonctionner ensemble dans un projet réel, c'est une architecture API-first : chaque couche expose une interface contractuelle, documentée, versionnée.
vLLM expose /v1/* (compatibilité OpenAI). OpenWebUI expose sa propre API REST. Vos applications métier consomment ces APIs via des clients dédiés. L'ensemble est découplé : vous pouvez remplacer vLLM par une autre implémentation sans toucher au reste de la stack.
Sans API-first, tout s'effondre — voici pourquoi
La tentation est de tout câbler directement : l'application appelle vLLM, l'interface appelle vLLM, les agents appellent vLLM. En développement, ça tourne. En production, les problèmes s'accumulent.
Sans couche API-first, vous héritez de :
- Des credentials LLM dispersés dans plusieurs applications
- Aucun point central pour monitorer les coûts d'inférence (tokens, latence, erreurs)
- L'impossibilité de router intelligemment selon le modèle ou la charge
- Aucune mise en cache des réponses identiques
- Une dépendance directe de chaque application à l'implémentation du backend LLM
Avec une couche API-first centrale :
Un service proxy (que nous construisons en général en FastAPI ou Hono) centralise l'accès à vLLM. Il expose une API unifiée vers l'amont, gère l'authentification, le logging, le rate limiting et le routing. Les applications et les agents consomment ce proxy — jamais vLLM directement.
Quand vous changerez de modèle ou ajouterez un second backend d'inférence (un second nœud GPU pour un modèle spécialisé, par exemple), le changement est transparent pour toutes les applications clientes.
C'est exactement le même principe que l'architecture API-first appliquée aux CMS headless ou aux plateformes SaaS : le contrat d'interface est stable, l'implémentation peut évoluer librement.
L'assemblage concret : comment on câble tout ça
Applications métier, OpenWebUI et agents IA s'adressent tous à un proxy central (FastAPI ou Hono), qui est le seul à dialoguer avec vLLM — lequel fait tourner le modèle en local sur GPU. Voici les quatre couches dans le détail.
Couche inférence — vLLM tourne sur un serveur GPU (A100, H100 ou A40 selon le modèle). Le endpoint /v1/chat/completions est exposé en interne uniquement, jamais directement accessible depuis l'extérieur.
Couche proxy — Un service léger gère l'authentification par clé API, le logging des requêtes (modèle appelé, tokens consommés, latence), le rate limiting par client, et optionnellement un cache sémantique pour les requêtes fréquentes.
Couche interface — OpenWebUI est configuré pour pointer vers le proxy, pas vers vLLM directement. Les utilisateurs internes accèdent à OpenWebUI pour leurs interactions quotidiennes. Le RAG intégré leur permet d'interroger des documents internes sans qu'ils ne quittent l'infrastructure.
Couche agents — Les agents IA (orchestrés via n8n, des scripts Python ou des services dédiés) consomment le proxy par clé API dédiée. Leurs appels sont tracés et auditables séparément des usages interactifs.
Ce que ça change vraiment dans vos projets web
Intégrer cette stack dans un projet concret — une plateforme Drupal, un SaaS Next.js, un back-office métier — change plusieurs choses en profondeur.
Vos LLMs connaissent votre contexte. Via le RAG d'OpenWebUI ou des appels directs avec contexte injecté, les agents IA opèrent sur votre base de données, vos contenus, vos logs — sans que ces données ne franchissent les frontières de votre infrastructure.
Vous maîtrisez les coûts. L'inférence locale a un coût fixe (le serveur GPU). Plus de facturation au token, plus de mauvaises surprises en fin de mois. Pour des usages intensifs (traitement de gros volumes de contenus, agents en continu), l'équation économique devient franchement favorable passé un certain volume.
Vous restez souverains sur les modèles. Vous choisissez la version exacte du modèle déployé. Une mise à jour chez OpenAI ne casse pas vos prompts du jour au lendemain. Vous validez les changements de modèle avant tout déploiement.
La conformité est documentable. Pour les projets soumis à des contraintes RGPD strictes ou à des certifications sectorielles, vous pouvez démontrer que les données ne quittent pas votre périmètre. Avec une API externe, c'est difficile, voire impossible.
Les pièges classiques (et comment ne pas y tomber)
Cette stack n'est pas triviale à opérer. Quelques points d'attention à ne surtout pas négliger :
Le dimensionnement GPU est critique. vLLM avec un modèle 7B nécessite environ 16 Go de VRAM. Un 13B en demande 26 Go. Un 70B en quantification 4 bits, environ 40 Go. Sous-dimensionner, c'est accepter une inférence lente ou des requêtes qui échouent sous charge.
Le cold start des modèles. Charger un modèle en mémoire GPU prend du temps — de 30 secondes à 2 minutes selon la taille. Dans une architecture serverless ou auto-scaling, ce délai de démarrage est rédhibitoire. Mieux vaut maintenir le serveur chaud en permanence.
La gestion des versions de modèles. Quand vous mettez à jour un modèle, les prompts qui fonctionnaient peuvent changer de comportement. Un système de versioning et des tests de régression sur vos prompts sont indispensables en production. Pas une option.
L'observabilité. Sans monitoring (tokens consommés, latence par requête, taux d'erreur), vous volez à l'aveugle. Nos déploiements vLLM intègrent systématiquement des tableaux de bord Grafana pour suivre la santé de l'inférence en temps réel.
Assembler une stack IA privée fonctionnelle n'est pas hors de portée. La faire tourner de manière fiable, sous charge, en production, avec une architecture qui résiste à l'évolution des modèles et des besoins — c'est là que l'expérience compte.
Nous avons bâti et opérons ce type d'infrastructure pour nos propres usages et pour des clients. Si vous évaluez l'option d'une stack IA privée, parlons-en.
Pour compléter votre lecture : notre guide sur le déploiement d'OpenWebUI avec vLLM, notre approche de la souveraineté des données, et comment nous orchestrons les agents IA dans nos pipelines.


